In my last post, I showed how to use the Segment Anything Model with prompts to improve the segmentation output, in it I decided that using bounding boxes to prompt the model yielded the best results for my purposes.
In this post I will try to describe a tiny, but slightly complex, app I made with the help of GitHub Copilot. This app is made with vanilla JavaScript and HTML uses SAM in the backend to extract the cutouts along with the bounding polygons for further use in my ultimate collection display.
Before we dive into a mess of code, have a look at the app I created:
(if you just want the code, go to the end of this post)
Requirements
The app I created needed to:
- Allow me to draw boxes on an image,
- perform image segmentation using the drawn box as a prompt.
- Once the image semgmentation is done, show the candidate cutouts and allow me to select the best and,
- give each one of them a unique identifier and a name.
Solution
In the end, I created a client-server app:
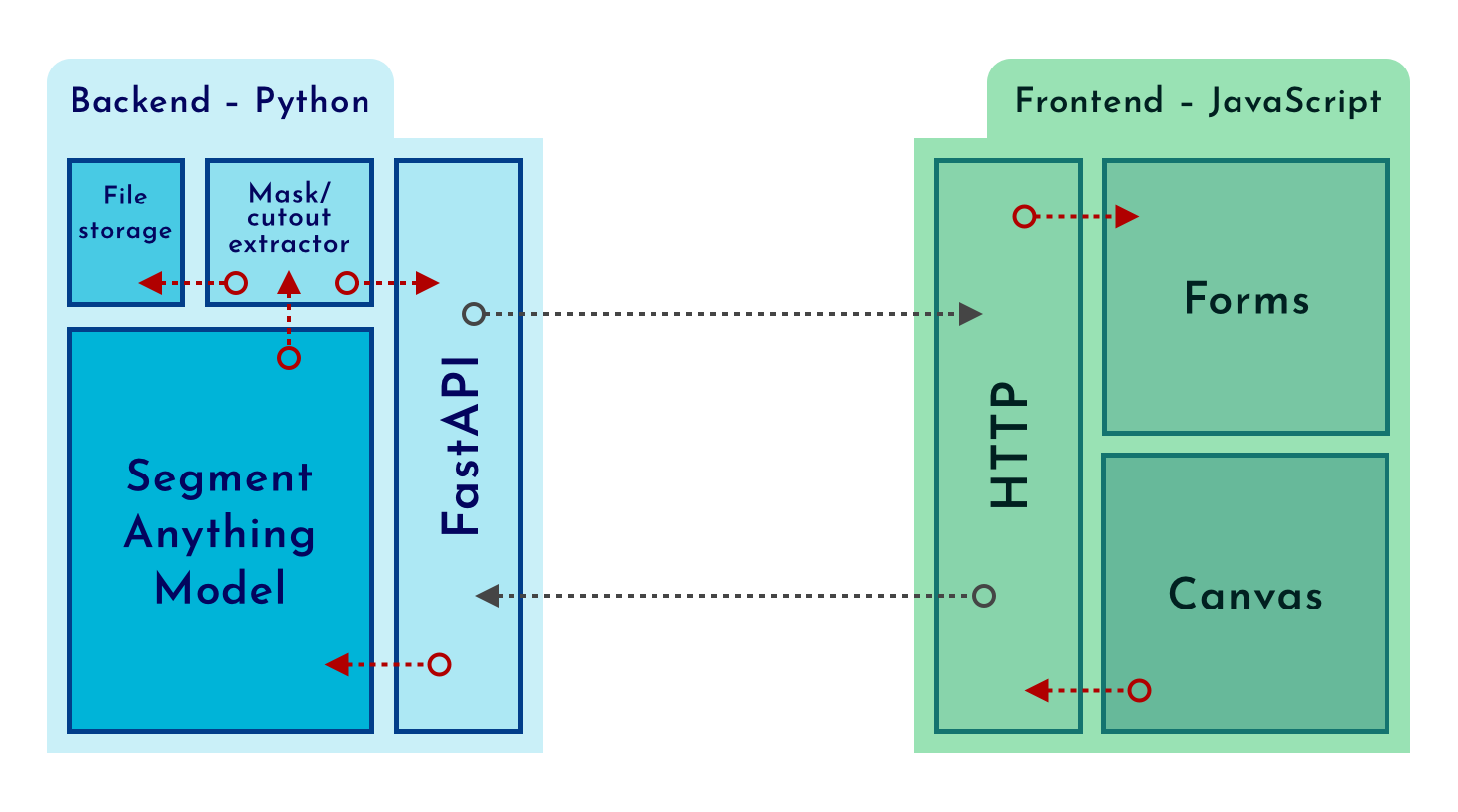
For the backend, the obvious decision was Python, since the Segment Anything Model is readily accessible in that language, and it is the language I know the most.
The client app is done with vanilla JavaScript, CSS and HTML; Using the canvas API it is effortless to draw bounding boxes over an image, and all the mouse events help us send the necessary data to extract a cutout.
Implementation
Project Structure Overview
The project consists of several interconnected components, including a FastAPI backend, HTML5 and JavaScript for the frontend, and CSS for styling. Here’s a breakdown of the key files and their roles:
web/labeller.py: The core backend file built with FastAPI. It handles route definitions, image manipulations, and interactions with the image segmentation model.web/static/app.css: Contains CSS styles to enhance the appearance of the application.web/static/app.js: Manages the frontend logic, particularly the interactions on the HTML5 Canvas where users draw annotations.web/templates/index.html.jinja: The Jinja2 template for the HTML structure, dynamically integrating backend data.web/resources.py: Manages downloading necessary resources like images and model files.web/sam.py: Integrates the machine learning model for image segmentation.
Out of these files, perhaps the most important ones are the the one that manages the frontend logic and the core of the app; will try my best to describe them below:
web/static/app.js
The script starts by setting up an environment where users can draw rectangular boxes on an image loaded into a canvas element. This functionality is an essential part of the app, since these boxes will be the prompts to the segment anything model in the backend.
1. Initialization on Window Load:
The script begins execution once the window has fully loaded, ensuring all HTML elements, especially the <canvas> and <img>, are available to manipulate.
window.addEventListener('load', function() {
const canvas = document.getElementById('canvas');
const ctx = canvas.getContext('2d');
const img = document.getElementById('image');
const results = document.getElementById('results');
const contours = [];2. Canvas and Context Setup:
Here, the canvas dimensions are set to match the image dimensions, and the image is then drawn onto the canvas. This forms the base on which users will draw the bounding boxes.
canvas.width = img.width;
canvas.height = img.height;
ctx.drawImage(img, 0, 0);3. Drawing Interactions:
Listeners for mousedown, mousemove, and mouseup events are added to the canvas to handle drawing:
- Create a variables to hold the mouse position and the drawing state:
let startingMousePosition = { x: 0, y: 0 };
let isDrawing = false;- Start Drawing: On
mousedown, it captures the starting point where the user begins the draw interaction.
canvas.addEventListener('mousedown', function(e) {
startingMousePosition = { x: e.offsetX, y: e.offsetY };
isDrawing = true;
});
- Drawing in Progress: The
mousemoveevent updates the drawing in real-time, showing a visual feedback of the rectangle being drawn on the canvas via theredrawCanvasand thedrawBoxfunctions.
canvas.addEventListener('mousemove', function(e) {
if (isDrawing) {
const currentX = e.offsetX;
const currentY = e.offsetY;
redrawCanvas();
drawBox(startingMousePosition.x, startingMouse-Position.y, currentX - startingMousePosition.x, currentY - startingMousePosition.y);
}
});
- End Drawing: The
mouseupevent finalises the drawing and optionally sends the drawn box data to the server using thesendBoxDatafunction.
canvas.addEventListener('mouseup', function(e) {
if (isDrawing) {
const endX = e.offsetX;
const endY = e.offsetY;
const box = {
x1: Math.min(startingMousePosition.x, endX),
y1: Math.min(startingMousePosition.y, endY),
x2: Math.max(startingMousePosition.x, endX),
y2: Math.max(startingMousePosition.y, endY)
};
sendBoxData(box);
redrawCanvas();
isDrawing = false;
}
});
4. Server Interaction:
Upon completing a drawing, the box data is sent to the server using a fetch call. This allows the application to process the box. This processing involves using the segment anything model to extract the candidate cutouts and returning them to be presented to the user using the createForm function:
function sendBoxData(box) {
fetch('/cut', {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify(box)
})
.then(response => response.json())
.then(data => {
results.innerHTML = '';
data.results.forEach(result => {
const t = createForm(result);
results.appendChild(t);
});
})
.catch(error => {
console.error('Error:', error);
});
}5. Dynamic Form Generation:
Responses from the server include an image and an identifier, that is used to create and populate forms dynamically. Using Mustache.js for templating, the script generates HTML forms based on this data, which are then inserted into the DOM, allowing further user interaction.
const template = `
<div class="form-container">
<div class="image-container">
<img src="{{image}}">
</div>
<form action="/select_cutout" method="POST">
<input type="text" name="name" placeholder="Name">
<input type="hidden" name="id" value="{{id}}">
<button type="submit">Select</button>
</form>
</div>
`;
function createForm(result) {
const rendered = Mustache.render(template, {
id: result.id,
image: result.image
});
const div = document.createElement('div');
div.innerHTML = rendered.trim();
return div.firstChild;
}
6. Utility Functions:
Several utility functions handle repetitive tasks:
redrawCanvas: Clears and redraws the canvas, useful for updating the view when needed.
function redrawCancas() {
ctx.clearRect(0, 0, canvas.width, canvas.height);
ctx.drawImage(img, 0, 0);
contours.forEach(points => {
drawPolygon(points);
});
}drawBox: Draws rectangles based on coordinates, the pins that have already been cut.
function drawBox(x, y, width, height, fill = false) {
ctx.beginPath();
ctx.rect(x, y, width, height);
ctx.strokeStyle = 'red';
if (fill) {
ctx.fillStyle = '#ff000033';
ctx.fill();
}
ctx.stroke();
}drawPolygon: A more complex drawing function that can render polygons, used here to illustrate the capability to handle various shapes.
function drawPolygon(points) {
ctx.beginPath();
ctx.moveTo(points[0][0], points[0][1]);
points.forEach(point => {
ctx.lineTo(point[0], point[1]);
});
ctx.fillStyle = '#ff0000FF';
ctx.closePath();
ctx.fill();
ctx.stroke();
}These utility functions are essential for managing the visual elements on the canvas, allowing for efficient updates and complex graphical operations like drawing polygons and boxes.
web/labeller.py
1. Environment Setup and Initialisations:
The application begins with setting up the FastAPI environment and configuring static file paths and template directories. This setup is crucial for serving static content like images and CSS, and for rendering HTML templates.
app = FastAPI()
app.mount("/static", StaticFiles(directory="web/static"), name="static")
templates = Jinja2Templates(directory="web/templates")
The image to annotate and the model to use are downloaded or loaded into the application, ensuring that all necessary components are available for image processing and analysis.
resources = download_resources()2. Image Loading and Preprocessing:
The image to annotate is loaded and preprocessed. This involves reading the image from a path, converting it to an appropriate colour format, and resizing it to a manageable size. This resizing is particularly important to ensure that the processing is efficient.
original_image = cv2.cvtColor(cv2.imread(str(resources["image_path"])), cv2.COLOR_BGR2RGB)
image_to_show = Image.fromarray(original_image)
image_to_show = image_to_show.resize((desired_image_width, int(image_to_show.height * ratio)))
3. Model Loading for Image Segmentation:
The segmentation model is loaded, configured, and prepared to predict masks based on user-defined annotations.
mask_predictor = get_mask_predictor(resources["model_path"])
mask_predictor.set_image(original_image)
4. Web Routing and Request Handling:
FastAPI routes handle different types of web requests. The main route serves the annotated image along with tools for the user to interact with. This is done through a both POST and GET request which renders an HTML template with the image and existing annotations.
@app.get("/")
@app.post("/")
def get_index(request: Request):
img = turns_image_to_base64(image_to_show)
existing_cutouts = []
for file in os.listdir(selected_folder):
if file.endswith(".json"):
with open(f"{selected_folder}/{file}") as f:
metadata = json.load(f)
existing_cutouts.append(metadata)
data = {
"request": request,
"image": img,
"width": image_to_show.width,
"height": image_to_show.height,
"existing_cutouts": existing_cutouts,
"ratio": ratio,
}
return templates.TemplateResponse("index.html.jinja", data)
5. Image Annotation and Segmentation:
When a user submits a bounding box annotation, the coordinates are scaled back to the original, unresized image and processed to segment the image. The application uses the model to predict the mask and then extracts the relevant part of the image based on these masks.
Apart from the extracted image cutouts, metadata is saved to a temporary folder, so that when a user selects a given cutout, they can be recovered.
@app.post("/cut/")
def post_cut(request: Request, box: BoundingBox):
box = np.array([box.x1, box.y1, box.x2, box.y2])
original_box = box / ratio
masks, _, _ = mask_predictor.predict(box=original_box, multimask_output=True)
results = []
for mask in masks:
uuid = str(uuid4())
cutout, bbox = extract_from_mask(original_image, mask)
base64_cutout = turns_image_to_base64(cutout, format="PNG")
results.append({
"id": uuid,
"image": base64_cutout,
})
metadata = {
"uuid": uuid,
"bbox": {"x1": bbox[0], "y1": bbox[1], "x2": bbox[2], "y2": bbox[3]},
"original_bbox": {
"x1": original_box[0],
"y1": original_box[1],
"x2": original_box[2],
"y2": original_box[3],
},
"polygons": [poly.tolist() for poly in sv.mask_to_polygons(mask)],
}
with open(f"{temp_folder}/{uuid}.png", "wb") as f:
cutout.save(f, format="PNG")
with open(f"{temp_folder}/{uuid}.json", "w") as f:
f.write(json.dumps(metadata))
return {"results": results}6. Handling user selection of cutouts
After users mark and submit their desired cutout, this endpoint manages the user’s selection, moving the annotated image data from temporary storage to a selected folder and updating its associated metadata with new user-provided information (like a name for the annotation):
@app.post("/select_cutout/")
def post_select_cutout(request: Request, id: Annotated[str, Form()], name: Annotated[str, Form()]):
import shutil
# Move the PNG image from temporary to selected folder
shutil.move(f"{temp_folder}/{id}.png", f"{selected_folder}/{id}.png")
# Load the existing metadata for the selected annotation
with open(f"{temp_folder}/{id}.json") as f:
metadata = json.load(f)
metadata["name"] = name # Update the name field with user-provided name
# Write the updated metadata back to the selected folder
with open(f"{selected_folder}/{id}.json", "w") as f:
f.write(json.dumps(metadata))
# Redirect back to the main page after processing is complete
return RedirectResponse("/")7. Utility Functions for Image Manipulation:
Several utility functions facilitate image manipulation tasks like cropping the image based on the mask:
def extract_from_mask(image, mask, crop_box=None, margin=10):
image_rgba = np.zeros((image.shape[0], image.shape[1], 4), dtype=np.uint8)
alpha = (mask * 255).astype(np.uint8)
for i in range(3):
image_rgba[:, :, i] = image[:, :, i]
image_rgba[:, :, 3] = alpha
image_pil = Image.fromarray(image_rgba)
if crop_box is None:
bbox = Image.fromarray(alpha).getbbox()
crop_box = (
max(0, bbox[0] - margin),
max(0, bbox[1] - margin),
min(image_pil.width, bbox[2] + margin),
min(image_pil.height, bbox[3] + margin),
)
cropped_image = image_pil.crop(crop_box)
return cropped_image, crop_boxAnd converting images to a web-friendly format to be sent as responses to the front end.
def turns_image_to_base64(image, format="JPEG"):
buffered = BytesIO()
image.save(buffered, format=format)
img_str = base64.b64encode(buffered.getvalue()).decode("utf-8")
return "data:image/jpeg;base64," + img_strThese functions ensure that the application can handle image data efficiently and render it appropriately on the web interface.
Libraries I used
- FastAPI: A web framework for building APIs (and web pages). It is used as the backbone of the application to handle web requests, routing, and server logic, and orchestrates the overall API structure. Although not used here, FastAPI provides robust features such as data validation, serialisation, and asynchronous request handling.
- OpenCV (cv2): OpenCV is a powerful library used for image processing operations. It is utilised to read and transform images, such as converting colour spaces and resizing images, which are essential pre-processing steps before any segmentation tasks.
- NumPy: This library is fundamental for handling arrays and matrices, such as for operations that involve image data. NumPy is used to manipulate image data and perform calculations for image transformations and mask operations.
- PIL (Pillow): The Python Imaging Library (Pillow) is used for opening, manipulating, and saving many different image file formats. Here it is specifically used to convert images to different formats, handle image cropping, and integrate alpha channels to extract the cutouts.
- Supervision: Although not yet a widely known library, this powerful library provides a seamless process for annotating predictions generated by various object detection and segmentation models; in this case, I used it to evaluate the results of SAM, and to convert its predictions to Polygon masks.
- Mustache.js: This is a templating engine used for rendering templates on the web. In your application, Mustache.js is used to dynamically create HTML forms based on the data received from the server, such as image cutouts and identifiers.
Closing thoughts
I hope I did not bore you to death with some of these deep dives into my (and some of my friendly coding assistant’s) code – I tried my best to be thorough. But if you still have doubts do not hesitate to reach out to me.
Believe it or not, this app is not complete yet, there is some other functionality yet to be implemented:
- A way to easily recover the selected cutouts
- A way to match already existing cutouts so that when the user selects the same cutout we don’t duplicate entries
- A way to handle updated canvas pictures, because what is going to happen when I inevitably expand my collection?
I will explore these details in the next blog post in the series.
